


Hallo zusammen,
heute möchte ich meine Erfahrungen zu Dynamics NAV Performance teilen. Dabei gibt es ein paar Dinge die meist schnell eingestellt sind und für verbesserte Leistung sorgen. Performanceprobleme können in jeder Dynamics NAV Datenbank auftreten. Dabei sind auch ältere Tipps dabei. Dies soll einen grundlegenden Überblick über die Einstellungen geben, auf die ich bei Installationen besonders achte.
Dynamics NAV Service Tier Einstellungen
Diese Werte stehen in der Datei „CustomSettings.config“ im Verzeichnis der Service Tier zur Verfügung. Sie können über die Dynamics NAV Administration oder über einen Editor direkt in der Konfigdatei geändert werden. Nach Änderung eines Wertes ist ein Neustart des Service Tier notwendig, damit die Einstellungen auch greifen.
MetadataProviderCacheSize: Diese Option steht seit Dynamics NAV 2009 RTC zur Verfügung und hat einen Standardwert von 150. Hiermit wird angegeben, wie viele Objekte in Cache gespeichert werden. Dieser Wert sollte so gewählt werden, dass alle genutzten Objekte auch im Cache gespeichert werden. Wird der Wert auf 5000 oder höher gesetzt, wird jedes Objekt auch im Cache gespeichert. Es ist zu empfehlen den Wert entsprechend zu erhöhen.
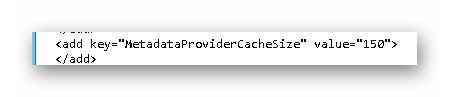
MaxConcurrentCalls: Dieser Wert bestimmt, wie viele gleichzeitige Anfragen von den Clients abgeschickt werden können. Dieser Wert kann ebenfalls erhöht werden. Als Richtwert nehme ich die maximal gleichzeitig angemeldete Benutzeranzahl auf der Service Tier x 2. Arbeiten also max. 20 Benutzer auf der Service Tier, dann verändere ich den Wert auch nicht. Der Wert steht ab NAV 2009 RTC zur Verfügung.
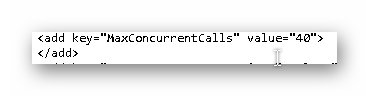
DisableSmartSQL: Ab NAV 2015 steht die Eigenschaft „DisableSmartSQL“ zur Verfügung. Diese Option ist standardmäßig nicht aktiviert. Das sollte auch nicht verändert werden. Wenn die Service Tier mit SmartSQL arbeitet, werden Abfragen gebündelt statt einzeln an den SQL Server übertragen.
Beispiel: Wird die Kontaktliste geöffnet und dort ist eine Factbox mit Flowfeldern enthalten, welche Daten aus den Aktivitätenprotokollposten anzeigt, dann schickt NAV ein kombiniertes SELECT für die Kontakttabelle und die Aktivitätenprotokollposten ab. Ist SmartSQL deaktiviert, dann werden die Information einzeln abgefragt.
Dieser Wert sollte dann temporär aktiviert werden, wenn Performanceproblemen auf die Schliche kommen möchte. Ab Dynamics NAV 2017 meldet die Service Tier in der Ereignisanzeige nämlich auch langsame Skripte.
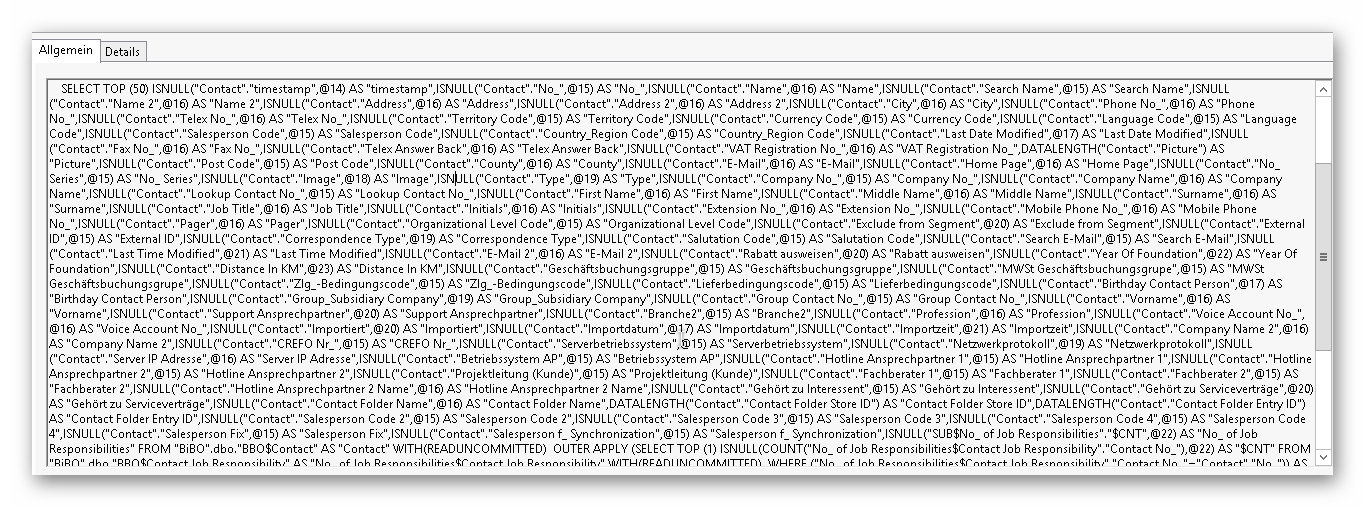
Das sieht beispielsweise so aus:

In diesen Fall dauert die Abfrage auf ein Individualfeld „Work Description“ im Verkaufskopf länger als 10 Sekunden. Dabei werden zwar die Filter für die Felder „Document Type“ und „No.“ nicht angezeigt, aber diese Meldungen in der Ereignisanzeige können Indikatoren auf Probleme in Zusammenhang mit dem Feld sein. Es besteht die Möglichkeit, dass es kein Schlüssel für das Feld „Work Description“ gibt. Es gibt aber auch deutlich komplexere Meldung, wie diese hier:
In diesem Fall kann es helfen „DisableSmartSQL“ zu aktivieren. Damit kann der langsame Teil besser identifiziert werden, da kein kombiniertes SQL Statement mehr übertragen wird. Sind die Probleme gefunden, sollte „DisableSmartSQL“ wieder deaktiviert werden.
Compile and Load Business Application: Die Service Tier speichert Teile der Anwendung bereits im Arbeitsspeicher und verkürzt somit Antwortzeiten nachdem die Service Tier neugestartet wurde. Daher ist meine Empfehlung diesen Option zu aktivieren bzw. aktiviert zu lassen. Diese Option steht ab Dynamics NAV 2016 zur Verfügung.
Details dazu auch hier zu finden: https://msdn.microsoft.com/de-de/library/hh174007(v=nav.90).aspx
Data Cache Size: Dieser Wert gibt an, wie viel Arbeitsspeicher eine Service Tier für das Cachen von Daten verbrauchen darf. Dabei sind die Werte wie folgt aufgeteilt:
9 -> 2 hoch 9 = 512 MB
10 -> 2 hoch 10 = 1.024 MB
11 -> 2 hoch 11 = 2.048 MB
12 -> 2 hoch 12 = 4.096 MB
13 -> 2 hoch 13 = 8.192 MB
14 -> 2 hoch 14 = 16.384 MB
15 -> 2 hoch 15 = 32.768 MB
Diese Eigenschaft wird oft angepriesen, allerdings habe ich hierdurch kaum Performanceverbesserungen gespürt. Diese Einstellung kann man also im Hinterkopf behalten, aber es sollte nicht zu viel erwartet werden.
SQL Server Einstellung
Am meisten kann man jedoch direkt am SQL Server optimieren. Dafür gibt es folgende Einstellungen
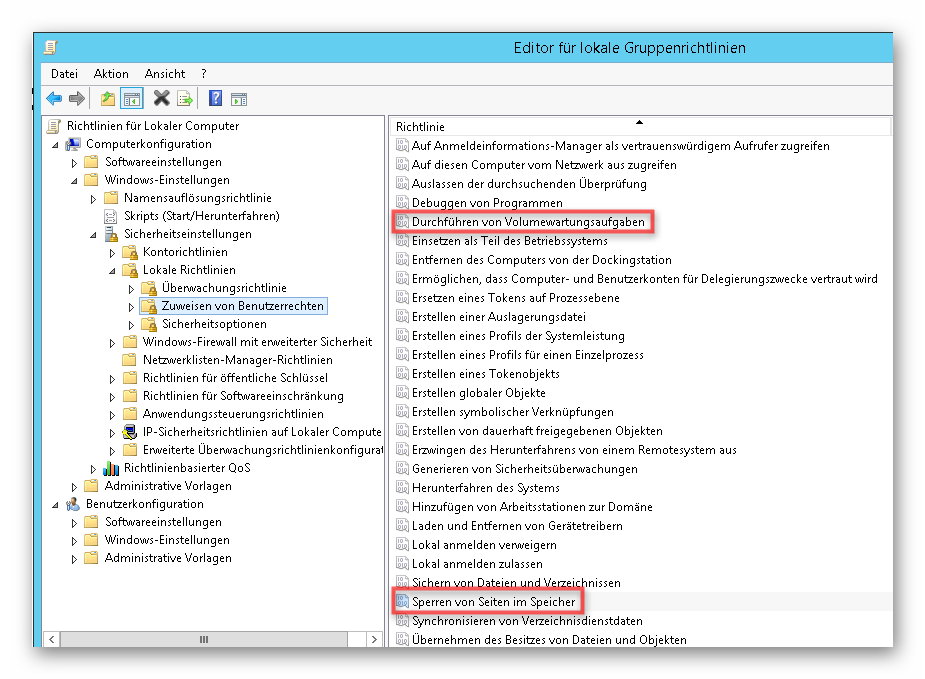
Gruppenrichtlinien: In den Gruppenrichtlinien am SQL Server sollten dir Rechte für den Dienstbenutzer des SQL Servers verändert werden. Zu empfehlen sind die folgenden Rechte:
- „Durchführen von Volumenwartungsaufgaben“ (mehr dazu hier: https://support.microsoft.com/de-de/help/2964518/recommended-updates-and-configuration-options-for-sql-server-2012-and)
- „Sperren von Seiten im Speicher“ (mehr dazu hier: https://docs.microsoft.com/de-de/sql/database-engine/configure-windows/enable-the-lock-pages-in-memory-option-windows).
Die Gruppenrichtlinien erreicht man wie folgt.
– Ausführen: gpedit.msc / Öffnen von „Computerkonfiguration“ -> „Windows-Einstellungen“ -> „Sicherheitseinstellungen“ -> „Lokale Richtlinien“ -> „Zuweisen von Benuterrechten“
Arbeitsspeicher: Arbeitsspeicher ist eines der wichtigsten Ressourcen für den SQL Server. Sind Daten erst mal im Cache, dann werden diese auch schnell abgerufen. Dabei achte ich auf zwei Faustregeln.
– Festlegen von maximalen Arbeitsspeicher des SQL Servers: Das vermeidet, dass der SQL Server zu viel Arbeitsspeicher verwendet, sodass der SQL Server mit 99 % RAM-Auslastung den Server lahm legt. Es ist darauf zu achten, dass auch dem System etwas Arbeitsspeicher zur Verfügung steht.
Konstruiertes Beispiel: 16 GB stehen auf dem SQL Server zur Verfügung. Es läuft der SQL Server und ein Echtsystem, Testsystem, sowie ein NAS auf der Maschine. Hier habe ich den SQL Server auf 12 GB gesetzt. Prüft hier einfach, wie viel Kapazitäten ihr habt und justiert das Limit entsprechend (siehe https://technet.microsoft.com/de-de/library/ms191144(v=sql.105).aspx).

– Erhöhung des Arbeitsspeichers: Es kann zu starken Verbesserungen kommen, wenn der Maximalwert vom SQL Server voll genutzt wird (kann per Ressourcenmonitor geprüft werden) und bei gleicher Aktivität Dynamics NAV mal langsam und mal schnell ist. Das kann dann dafür sprechen, das Daten mal im Cache sind und mal nicht. Nach Erhöhung des Arbeitsspeichers sollte ebenfalls das maximale Limit im SQL Server erhöht werden.
Indexanalyse: Mit der Indexanalyse können erhebliche Verbesserungen der Leistung herbeigeführt werden. Dafür gibt es grundsätzlich zwei Skripte:
-> Skript zur Ermittlung fehlender Schlüssel
SELECT
CONVERT (DECIMAL (28,1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS improvement_measure,
mid.statement AS table_name,
mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
migs.avg_user_impact,
migs.unique_compiles,
migs.user_seeks,
migs.user_scans,
migs.last_user_seek,
migs.last_user_scan,
'CREATE INDEX [missing_index_'
+ CONVERT(VARCHAR, mig.index_group_handle) + '_'
+ CONVERT(VARCHAR, mid.index_handle) + '_'
+ LEFT(PARSENAME(mid.statement, 1), 32) + ']' + ' ON '
+ mid.statement
+ ' (' + ISNULL(mid.equality_columns, '')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL(mid.inequality_columns, '') + ')'
+ ISNULL(' INCLUDE (' + mid.included_columns + ')', '')
AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC;
Als Ergebnis bekommt man eine Tabelle mit der Auswertung der Statistiken des SQL Servers. Dabei soll die Spalte „improvement_measure“ eine grobe Wertung des Einflusses darstellen. Umso höher der Wert umso wahrscheinlicher, dass nach der Anlage des fehlenden Index das System in diesem Bereich schneller ist. Zusätzlich wird die betroffene Tabelle und die betroffenen Felder angezeigt.
Die Spalte user_seeks ist für mich besonders wichtig. Hieran kann ich erkennen, wie oft der SQL Server den Index gebraucht hätte. Einträge mit höheren Werte werden häufiger gebraucht und haben damit auch einen höheren Einfluss. Wenn die Datenbank schon zwei Jahre läuft und es 5 Seeks für einen Index gibt, dann sind diese in der Regel nicht sehr bedeutsam. Da gibt es zwar auch Ausnahmen, auf die ich jetzt nicht weiter eingehe.
In der Spalte „last_user_seek“ kann man auch sehen, wann der Index das letzte mal benötigt wurde.

In diesem Beispiel sieht man, dass es einen Eintrag mit ca. 28.000 user_seeks gibt. Diesen Index schaue ich mir dann näher an. Welche Tabelle ist betroffen, welche Felder sind betroffen, welcher Prozess ist davon eventuell betroffen? In diesem Fall ist Bemerkungstabelle betroffen. Als Lösung gibt es nun zwei Möglichkeiten:
- Index (Schlüssel) in Dynamics NAV anlegen (falls möglich) – Dies gilt dann für alle Mandanten – einige Schlüssel können nicht in NAV angelegt werden
- Index über den SQL Server anlegen – Dies gilt dann nur für den betroffenen Mandanten – In der Spalte „create_index_statement“ wird ein Skript vorbereitet, welches in eine neue Abfrage kopiert werden kann. Führt man diese dann aus, wird der Index nur auf dem SQL Server angelegt.
Es gibt hier verschiedene Ansätze, wann man etwas wie tun sollte. Pauschal gesagt, kann man hiermit schnell fehlende Indexe anlegen und kann damit auch Performancesteigerungen erreichen. Dennoch ist eine präzise Analyse der „langsamen“ Vorgänge besser, als einfach Indexe anzulegen. Die Anlage von Indexen kann im Livebetrieb vorgenommen werden. Es ist aber zu spüren, das heißt die Performance für NAV sinkt, während der SQL Server Indexe aufbaut.
Ein Tipp noch am Rande: Steht im Create Index Statement ein INCLUDE [timestamp] am Ende, dann kann das INCLUDE inkl. der folgenden Felder gelöscht werden. Das sind nämlich alle Felder der Tabelle.
Es ist ratsam diese Prüfungen regelmäßig durchzuführen. Dazu sollte auch geprüft werden, ob angelegte Schlüssel überhaupt positive Effekte erwirken konnten. Dazu gibt es das folgende Skript.
-> Skript zur Ermittlung, ob angelegte Indexe überhaupt verwendet werden
In diesem Skript werden euch alle Indexe angezeigt, die ihr mit dem oben genannten Skript angelegt habt. Ihr könnt hier sehen, wie oft die Indexe tatsächlich genutzt wurden und wie oft der SQL Server diesen Index auch mit aufgebaut hat. Zusätzlich besteht beispielsweise mit der Spalte „tsql_DROP“ die Möglichkeit den Index wieder zu löschen (Inhalt des Feldes in eine neue Abfrage kopieren und ausführen). Das macht vor allem dann Sinn, wenn dieser nie verwendet wurde. Dann kostet der Index nur Ressourcen und sollte wieder entfernt werden. Beachtet dabei, dass wenn die Werte in den Spalten „user_seeks“, „user_scans“, „user_lookups“, „user_updates“ alle NULL sind, dass es sich hier vermutlich um einen frisch angelegten Schlüssel handelt.
USE [databasename] -- change db name on demand
GO
SELECT object_name(sysidx.[object_id]) as [object_name],
sysidx.[name] as [index_name],
idxcol.key_columns,
idxcol.included_columns,
sysidx.filter_definition,
idxusg."user_seeks", idxusg."user_scans", idxusg."user_lookups", idxusg."user_updates",
'IF NOT EXISTS (SELECT TOP 1 NULL FROM sys.indexes (NOLOCK) WHERE object_name([object_id]) = ''' + object_name(sysidx.[object_id]) + ''' AND [name] = ''' + sysidx.[name] + ''')
CREATE INDEX [' + sysidx.[name] + '] ON [' + object_name(sysidx.[object_id]) + ']
(' + idxcol.key_columns + ')' +
CASE WHEN idxcol.included_columns is not null THEN '
INCLUDE
(' + idxcol.included_columns + ')' ELSE '' END +
CASE WHEN sysidx.filter_definition is not null THEN '
WHERE
' + sysidx.filter_definition + '' ELSE '' END + '
WITH (MAXDOP = 64, ONLINE = OFF, DROP_EXISTING = OFF);
'
as [tsql_CREATE],
'IF EXISTS (SELECT TOP 1 NULL FROM sys.indexes (NOLOCK) WHERE object_name([object_id]) = ''' + object_name(sysidx.[object_id]) + ''' AND [name] = ''' + sysidx.[name] + ''')
DROP INDEX [' + sysidx.[name] + '] ON [' + object_name(sysidx.[object_id]) + '];
'
as [tsql_DROP]
FROM
sys.indexes sysidx
LEFT OUTER JOIN sys.dm_db_index_usage_stats idxusg ON sysidx."object_id" = idxusg."object_id" AND sysidx."index_id" = idxusg."index_id"
JOIN (
SELECT Tab.[name] AS TableName,
Ind.[name] AS IndexName,
SUBSTRING ((
SELECT ', [' + AC.name + ']'
FROM
sys.[tables] AS T INNER JOIN sys.[indexes] I
ON T.[object_id] = I.[object_id]
INNER JOIN sys.[index_columns] IC
ON I.[object_id] = IC.[object_id] AND I.[index_id] = IC.[index_id]
INNER JOIN sys.[all_columns] AC
ON T.[object_id] = AC.[object_id] AND IC.[column_id] = AC.[column_id]
WHERE Ind.[object_id] = I.[object_id] AND Ind.index_id = I.index_id AND IC.is_included_column = 0
ORDER BY IC.key_ordinal
FOR XML PATH ('')) , 3, 8000) AS key_columns,
SUBSTRING ((
SELECT ', [' + AC.name + ']'
FROM
sys.[tables] AS T INNER JOIN sys.[indexes] I
ON T.[object_id] = I.[object_id]
INNER JOIN sys.[index_columns] IC
ON I.[object_id] = IC.[object_id] AND I.[index_id] = IC.[index_id]
INNER JOIN sys.[all_columns] AC
ON T.[object_id] = AC.[object_id] AND IC.[column_id] = AC.[column_id]
WHERE Ind.[object_id] = I.[object_id] AND Ind.index_id = I.index_id AND IC.is_included_column = 1
ORDER BY IC.key_ordinal
FOR XML PATH ('')) , 3, 8000) AS included_columns
FROM
sys.[indexes] Ind INNER JOIN sys.[tables] AS Tab
ON Tab.[object_id] = Ind.[object_id]
INNER JOIN sys.[schemas] AS Sch
ON Sch.[schema_id] = Tab.[schema_id]
UNION
SELECT Tab.[name] AS TableName,
Ind.[name] AS IndexName,
SUBSTRING ((
SELECT ', [' + AC.name + ']'
FROM
sys.[views] AS T INNER JOIN sys.[indexes] I
ON T.[object_id] = I.[object_id]
INNER JOIN sys.[index_columns] IC
ON I.[object_id] = IC.[object_id] AND I.[index_id] = IC.[index_id]
INNER JOIN sys.[all_columns] AC
ON T.[object_id] = AC.[object_id] AND IC.[column_id] = AC.[column_id]
WHERE Ind.[object_id] = I.[object_id] AND Ind.index_id = I.index_id AND IC.is_included_column = 0
ORDER BY IC.key_ordinal
FOR XML PATH ('')) , 3, 8000) AS key_columns,
SUBSTRING ((
SELECT ', [' + AC.name + ']'
FROM
sys.[views] AS T INNER JOIN sys.[indexes] I
ON T.[object_id] = I.[object_id]
INNER JOIN sys.[index_columns] IC
ON I.[object_id] = IC.[object_id] AND I.[index_id] = IC.[index_id]
INNER JOIN sys.[all_columns] AC
ON T.[object_id] = AC.[object_id] AND IC.[column_id] = AC.[column_id]
WHERE Ind.[object_id] = I.[object_id] AND Ind.index_id = I.index_id AND IC.is_included_column = 1
ORDER BY IC.key_ordinal
FOR XML PATH ('')) , 3, 8000) AS included_columns
FROM
sys.[indexes] Ind INNER JOIN sys.[views] AS Tab
ON Tab.[object_id] = Ind.[object_id]
INNER JOIN sys.[schemas] AS Sch
ON Sch.[schema_id] = Tab.[schema_id]
) idxcol ON object_name(sysidx.[object_id]) = idxcol.TableName AND sysidx.[name] = idxcol.IndexName
WHERE object_name(sysidx.[object_id]) not like 'ssi%'
AND sysidx.[name] like 'ssi%' or sysidx.[name] like 'missing_index_%'
ORDER BY 1,3,4
Cumulative Update: Für den SQL Server stellt Microsoft regelmäßig Updates zur Verfügung. Diese werden nicht automatisch bei Windows Updates bereitgestellt. Meines Wissens werden lediglich Service Packs für den SQL Server in Windows Updates bereitgestellt. Zwischen dem letzten Service Pack und dem letzten Cumulative Update (CU) können in der Realität Jahre liegen. Es ist daher ratsam ab und an den SQL Server zu aktualisieren.
Eine Übersicht der SQL Server Versionen, Service Packs & Cumulative Updates inkl. Downloadlinks findet ihr hier: http://sqlserverbuilds.blogspot.de/
Für die Installation eines Cumulative Update benötigt ihr das davor veröffentliche Service Pack. Bei der Installation wird der SQL Server gestoppt. Es wird also ein Wartungsfenster benötigt. In der Regel dauert die Installation nicht zu lange.
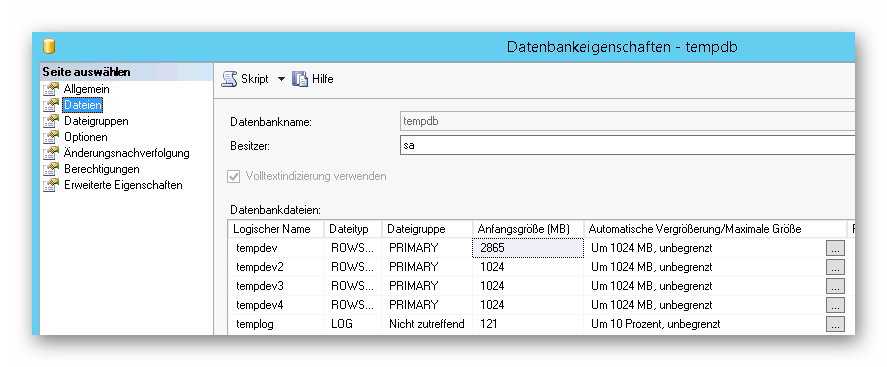
Aufteilung TempDB: Bei der TempDB handelt es sich um eine Systemdatenbank des SQL Servers. Stehen dem SQL Server mehr als ein CPU Kern zur Verfügung, kann die TempDB aufgeteilt werden. Pro lizenzierten Kern sollte es dann eine Tempdb Datei geben. Mit dem folgenden Skript kann die Tempdb aufgeteilt werden:
ALTER DATABASE tempdb ADD FILE (NAME = tempdev2, FILENAME = 'W:\tempdb2.mdf', SIZE = 1024, FILEGROWTH = 1024); ALTER DATABASE tempdb ADD FILE (NAME = tempdev3, FILENAME = 'X:\tempdb3.mdf', SIZE = 1024, FILEGROWTH = 1024); ALTER DATABASE tempdb ADD FILE (NAME = tempdev4, FILENAME = 'Y:\tempdb4.mdf', SIZE = 1024, FILEGROWTH = 1024); GO
Dabei kann die Tempdb auch auf verschiedene Festplatten aufgeteilt werden (siehe oben). Ob das nötig ist, ist im Einzelfall zu betrachten. Die TempDB kann über das SQL Management Studio gefunden werden.
Bei vier Kernen sieht die TempDB nach der Aufteilung so aus.
Alternative Quelle dazu: https://tristanmaritz.wordpress.com/2015/05/15/dynamics-nav-performance-tempdb/
Wartungsjobs: Die Indexierung der Datenbank sollte regelmäßig durchgeführt werden. Dafür ist ein Wartungsjob, der einmal pro Woche durchgeführt werden sollte, empfehlenswert.
Dafür werden für SQL Server 2014 oder ältere SQL Server Versionen ein manuelles Skript empfohlen. Dies ist in drei T-SQL Skripten aufgeteilt.
– T-SQL Skript 1: Umstellung auf Sicherheitsmodell „Simple“
USE [master] GO ALTER DATABASE [Databasename] SET RECOVERY SIMPLE WITH NO_WAIT GO ALTER DATABASE [Databasename] SET RECOVERY SIMPLE GO
– T-SQL Skript 2: Neuindexierung (Rebuild oder Reorganize) der Datenbank
USE [Databasename] GO SET NOCOUNT ON; DECLARE @objectid int; DECLARE @indexid int; DECLARE @partitioncount bigint; DECLARE @schemaname nvarchar(130); DECLARE @objectname nvarchar(130); DECLARE @indexname nvarchar(130); DECLARE @partitionnum bigint; DECLARE @partitions bigint; DECLARE @frag float; DECLARE @command nvarchar(4000); -- Conditionally select tables and indexes from the sys.dm_db_index_physical_stats function -- and convert object and index IDs to names. SELECT object_id AS objectid, index_id AS indexid, partition_number AS partitionnum, avg_fragmentation_in_percent AS frag INTO #work_to_do FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED') WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0;-- Declare the cursor for the list of partitions to be processed. DECLARE partitions CURSOR FOR SELECT * FROM #work_to_do;-- Open the cursor. OPEN partitions;-- Loop through the partitions. WHILE (1=1) BEGIN; FETCH NEXT FROM partitions INTO @objectid, @indexid, @partitionnum, @frag; IF @@FETCH_STATUS < 0 BREAK; SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name) FROM sys.objects AS o JOIN sys.schemas as s ON s.schema_id = o.schema_id WHERE o.object_id = @objectid; SELECT @indexname = QUOTENAME(name) FROM sys.indexes WHERE object_id = @objectid AND index_id = @indexid; SELECT @partitioncount = count (*) FROM sys.partitions WHERE object_id = @objectid AND index_id = @indexid;-- 30 is an arbitrary decision point at which to switch between reorganizing and rebuilding. IF @frag < 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE'; IF @frag >= 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD'; IF @partitioncount > 1 SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10)); EXEC (@command); PRINT N'Executed: ' + @command; END;-- Close and deallocate the cursor. CLOSE partitions; DEALLOCATE partitions;-- Drop the temporary table. DROP TABLE #work_to_do; GO
– T-SQL Skript 3: Umstellung auf Recovery Mode Full
-- Change security model back USE [master] GO ALTER DATABASE [Databasename] SET RECOVERY FULL WITH NO_WAIT GO ALTER DATABASE [Databasename] SET RECOVERY FULL GO
Ab SQL Server 2016 ist kein spezielles Skript mehr notwendig. Die Wartungspläne „Index neu organisieren“ und „Index neu erstellen“ können mittlerweile konfiguriert werden. Dabei bleiben die Skripte zur Umstellung des Recovery Modes bestehen. Lediglich das zweite T-SQL Skript (siehe oben) wird durch die Standardwartungspläne ersetzt.


Weitere Tipps
Antivirensoftware: Sollte eine Antivirensoftware auf der Maschine des SQL Servers oder der Dynamics NAV Service Tier installiert sein, dann sollte diese auch richtig konfiguriert werden.Auf dem SQL Server sollte keine Echtzeitüberprüfung auf Systemdatenbankdateien oder normale Datenbankdateien erfolgen. Dazu gibt es auch detaillierte Informationen von Microsoft: https://support.microsoft.com/de-lu/help/309422/how-to-choose-antivirus-software-to-run-on-computers-that-are-running
Auf dem Dynamics NAV Ordner sollten die Programmverzeichnisse von Dynamics NAV ausgeschlossen werden. Bei Performanceproblemen lohnt es sich auch mal, den Vorgang in einer Umgebung ohne oder mit deaktivierten Antivirensoftware nochmal zu testen. Antivirensoftware kann in bestimmten Situationen die Performance massiv verschlechtern.
Hardware: Bei der Hardware gibt es zwei Empfehlungen für Dynamics NAV und den SQL Server:
– Die Hardware (CPU, RAM, Festplatten) sollten exklusiv zur Verfügung gestellt werden.
– Verwendet falls möglich SSD Festplatten für die Datenbankdateien. Das wird die Performance erheblich steigern.Weitere Anforderungen an die Hardware hängen sicherlich von den spezifischen Anforderungen bzw. gleichzeitigen Nutzerzugriffen ab.
Ich hoffe das diese Tipps euch weiterhelfen. Einige Tipps habe ich durch die Zusammenarbeit mit Jörg Stryk und meinen Kollegen in diversen Projekten gelernt. Schaut auf jeden Fall auch bei ihm vorbei: http://blog.stryk.info/.
Pingback: Dynamics NAV / SQL Server Performance Tipps & Tricks - Robert's Dynamics NAV Entwickler Blog - Business Central/NAV Users - DUG
SmartSQL hat bei einem Kunden, der sehr viele FlowFields verwendet den genau gegenteiligen Effekt gehabt.
Eine Liste mit über 30 FlowFields ließ sich mit SmartSQL in ca. 20-25 Sekunden laden. Nachdem wir „DisableSmartSQL“ aktiviert haben wurde sie in 2-3 Sekunden geladen.
Wir haben den selben Effekt wie Gerald beschrieben. Nachdem wir “DisableSmartSQL” aktiviert haben wird die Liste mit ca. 20 Flowfields in 1-2 Sekunden geladen. Woher brauchte die Liste 10-15 Sekunden.
Gibt es da bereits neue Kenntnisse?
Das kann man so als Regel nicht festlegen. Bei einer Liste mit 20 Flowfields und 10-15 Sekunden Ladezeit würde ich mir die Execution Plans auf dem SQL Server ansehen. Da kann man dann auch sehen welche Probleme genau auftreten. Es kann auch sein, dass die Indexauswahl besser funktioniert, wenn die Flowfields einzeln geladen werden.
Es kann auch mit der NAV/BC Version zusammenhängen, da die SQL Queries nicht zwischen allen Versionen gleich sein müssen.
Pingback: Dynamics NAV / SQL Server Performance Tipps & Tricks - Robert's Dynamics NAV Entwickler Blog - Dynamics 365 Business Central/NAV User Group - Dynamics User Group